Hello there, it’s been a while! Today is a short retrospective of the underwhelming 2019 Squiggle tipping competition performance. We’ll be covering what went wrong, some key learnings and how to improve for next year.
It’s safe to say that AFLgains squiggle performance was not up to standard. Overall, the model managed 130 correct tips at an accuracy of 62.3% (3rd to last). We also came 2nd to last in bits, only managing 12.4 through the whole season. While the model did slightly better in Mean Absolute Error coming 12th, the results were overall quite substandard.
However, this is only the model’s first year competing and there are plenty of important learnings that I’m excited to take into next year.
Key learning 1: Building a model to predict the past is much easier than building a model to predict the future
No, I’m not talking about over fitting, I’m referring to putting code into production! One should never underestimate the extra plumbing and sense checking that is needed to put models into live systems so they can ingest constantly updating data and up-to-date predictions. It’s something that I wasn’t careful with and paid dearly for.
Before the season started, I set about trying to productionise my working model so that it would run live and automatically throughout the 2019 season. I put all my R code on an AWS EC2 instance so it would be accessible over the Internet and not reliant on my laptop being open. Instead of ingesting data from a csv on my laptop, I moved everything to Amazon S3 and connected via an API. I tested the system out and everything seemed to work fine. I used a package called cronR to run the script periodically and set the schedule for once a week.
The season started and everything seemed to work okay. After the first round however, something seemed off. The model got 1/9 while all other models tipped at least 3 correct. It was pretty strange, but I just put this down to my model being different (it was only one of three machine learning based models). Unfortunately, as the rounds continued it was evident that something was definitely wrong. In Round 4, the unthinkable happened and the model got 0/9 when everyone else got 4 or more. Just think about this for a second. Randomly guessing should get at least 4-5 tips correct. By the end of Round 4, the model was last place on the ladder, a massive 4 tips behind 2nd to last!
This wasn’t just a statistically anomaly, this was due to a bug in the code.

I was determined to find the bug and after a lot of searching and testing I eventually found it. During the data ingestion phase, all of the player statistics were being taken in as factors, not as characters as I had expected. When I turned them back into numbers using as.numeric(), it was turning them into their factored numbers and not their actual values! Needless to say, the reason why the model was making incorrect predictions was because the model was being fed garbage!
I managed to fix and bug after Round 5, and thankfully the model started to make much more sensible predictions. Unfortunately, I was still having a lot of trouble with the model running on AWS, so from Round 8 I switched to a new python based model, which will be the subject of another blog.
Learning 2: The competition can be lost at the beginning of the season
After I fixed the bug post Round 5, the model did very well. However, the damage was already done and it was very difficult to make up any ground the later the season went on. The reason why is that after the early rounds it’s already clear who the good and the bad teams are. Most models (mine included) were similar in who they tipped, with the only variability being the tipping confidence and predicted margin. Once you’re behind the 8-ball early, there’s almost no way of clawing yourself back.
Learning 3: Probability predictions and margin predictions don’t have to be coupled
In the AFL Gains model, margin predictions are related to probability predictions in a log-linear fashion. This means there is a monotonic relationship between the size of the margin and the confidence of the prediction. This does make sense - if you tip a 100 point win you’re probably quite confident in the result. However, there is no reason why the two predictions have to be coupled and indeed several models in the Squiggle competition have separate models for both tasks. Take a look at a comparison of AFL Lab v AFL Gains when plotting margin v confidence. The monotonic relationship in the AFL Gains model can clearly be seen, while AFL Lab has a positive yet stochastic relationship.
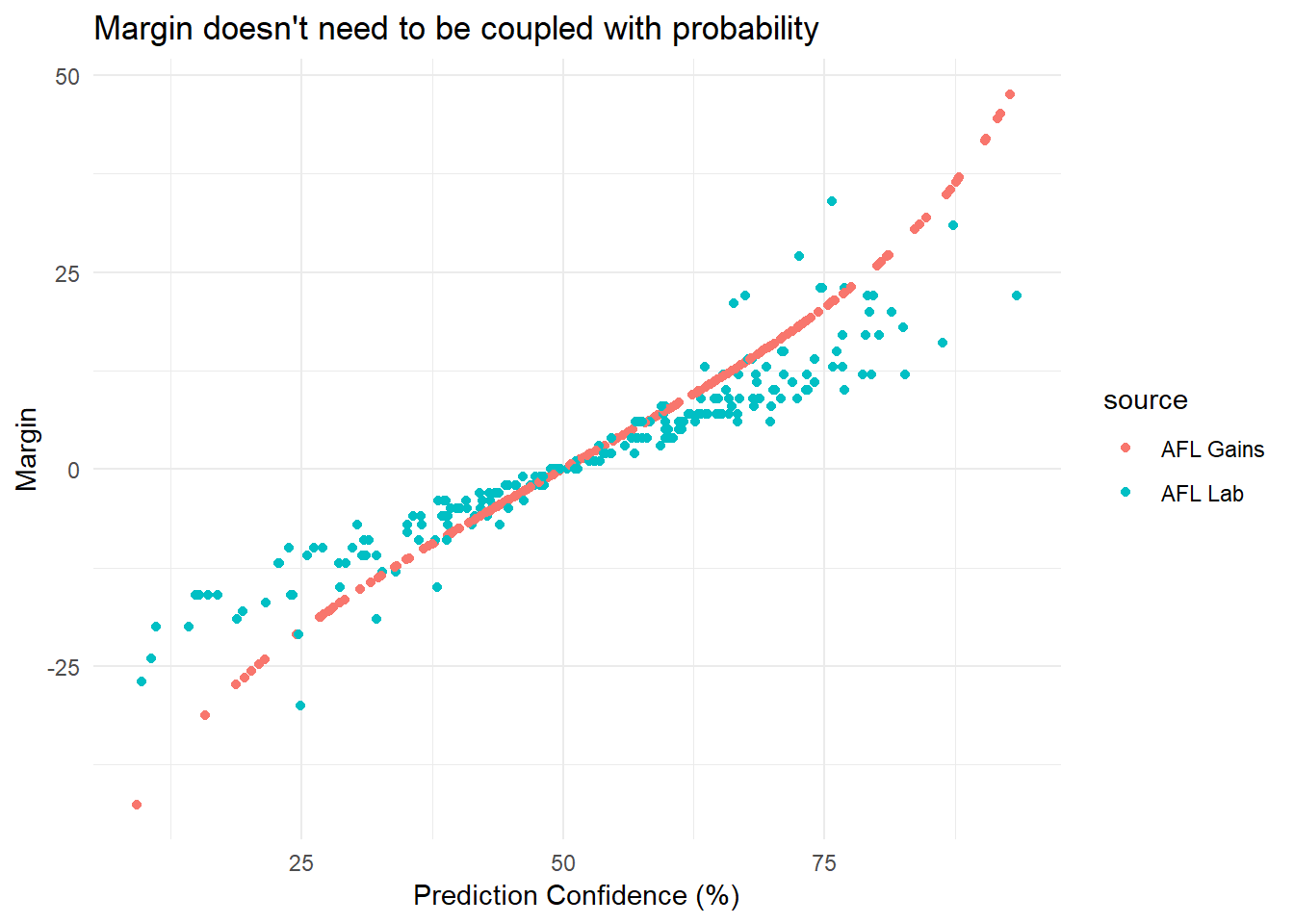
This is advantageous when AFL Lab is confident in the win, but wants to predict a margin that may be higher or lower depending on the attacking of defending capabilities of the teams involved. Decoupled margin and probability predictions will be a feature of the AFL Gains entry next year and is the topic of the next post!
Silver linings
So there were plenty of learnings, but is there anything we can be happy with? One positive is that once the bug was fixed and I made the switch to python, the model performed very well. In fact, running some analytics on this shows that the python model was actually one of the “better” performing models. While it still performed relatively poorly on total bits, it had equal best accuracy. MAE was also reasonably high (but far from the), probably due to the fact that confidence and margin were completely coupled.
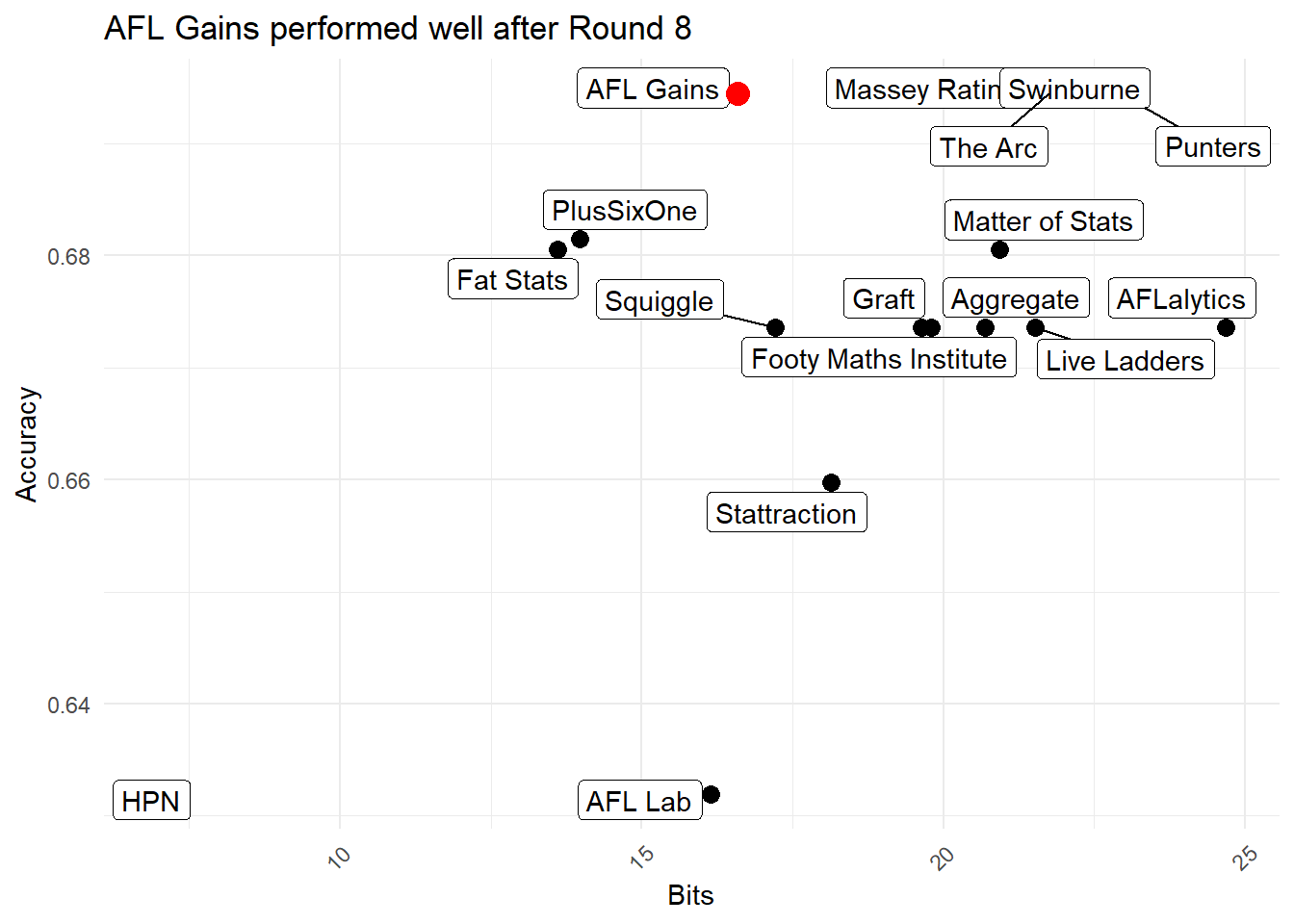
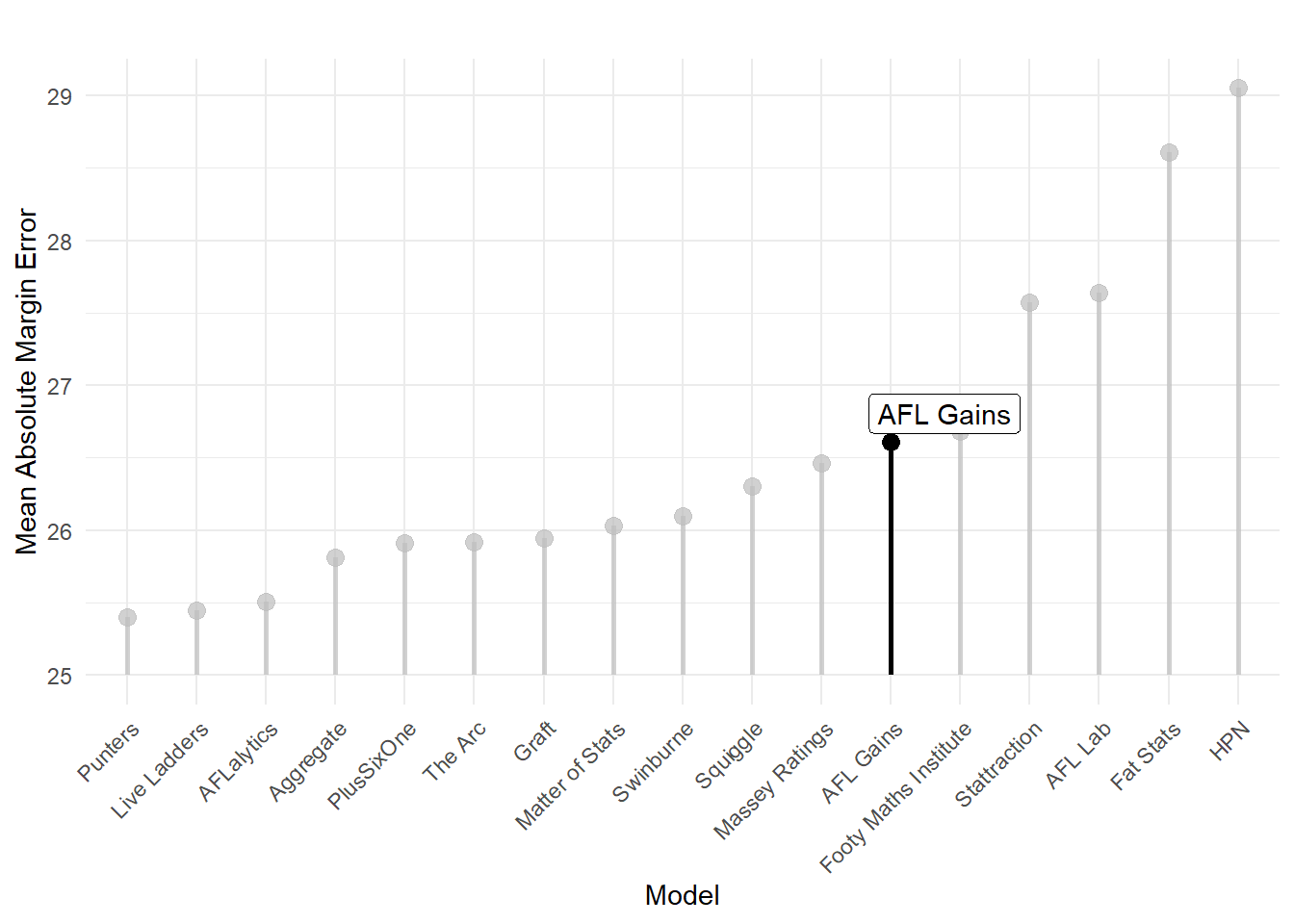
Having equal best accuracy is a small consolation, but gives me confidence to for next year’s competition. In particular, keep watch for the next post where I go into depth about the latest addition to the AFL Gains model family to decouple margin and probability predictions.